作者:手机用户2602898385 | 来源:互联网 | 2023-10-11 21:44
篇首语:本文由编程笔记#小编为大家整理,主要介绍了致景科技Java面经相关的知识,希望对你有一定的参考价值。
致景科技面经
- 一、Spring的特点
- 二、SpringIOC的了解
- 三、什么是SpringAOP
- 四、动态代理的实现
- 五、Springmvc原理
- 六、Springboot的启动流程
- 七、线程与进程的区别
- 八、线程之间怎么通信
- 九、进程之间怎么通信
- 十、线程安全问题,怎么解决
- 十一、常见的锁有哪些
- 十二、Kafka的底层原理,为什么那么快?
- 十三、为什么不用其它MQ,而使用Kafka?
- 十四、抽象类和接口的区别,以及使用方面?
- 十五、Redis的持久化机制详细说明?
一、Spring的特点
Spring 是一款开源的轻量级 Java 开发框架,旨在提高开发人员的开发效率以及系统的可维护性。Spring 框架是很多模块的集合,使用这些模块可以很方便地协助我们进行开发。
Spring 自带 IoC(Inverse of Control:控制反转) 和 AOP(Aspect-Oriented Programming:面向切面编程)、可以很方便地对数据库进行访问、可以很方便地集成第三方组件(电子邮件,任务,调度,缓存等等)、对单元测试支持比较好、支持 RESTful Java 应用程序的开发。
二、SpringIOC的了解
Spring通过一个配置 文件描述Bean 和Bean之间的依赖关系,利用Java的反射功能实例化Bean并建立Bean之间的依赖关系。Spring 的IoC容器在完成这些底层工作的基础上,还提供了Bean 实例缓存管理、Bean 生命周期管理、Bean实例代理、事件发布和资源装载等高级服务。
Spring 在启动时会从XML配置文件或注解中读取应用程序提供的Bean配置信息,并在Spring 容器中生成一份相应的Bean配置注册表:然后根据这张注册表实例化Bean.装配好Bcan 之间的依赖关系,为上层业务提供基础的运行环境。其中Bean缓存池为HashMap实现。
三、什么是SpringAOP
AOP(Aspect-Oriented Programming:面向切面编程)能够将那些与业务无关,却为业务模块所共同调用的逻辑或责任(例如事务处理、日志管理、权限控制等)封装起来,便于减少系统的重复代码,降低模块间的耦合度,并有利于未来的可拓展性和可维护性。
Spring AOP 就是基于动态代理的,如果要代理的对象,实现了某个接口,那么 Spring AOP 会使用 JDK Proxy,去创建代理对象,而对于没有实现接口的对象,就无法使用 JDK Proxy 去进行代理了,这时候 Spring AOP 会使用 Cglib ,这时候 Spring AOP 会使用 Cglib 生成一个被代理对象的子类来作为代理.
四、动态代理的实现
Spring提供了JDK 和CGLib 2种方式来生成代理对象,具体生成代理对象的方式由AopProxyFactory根据AdvisedSupport 对象的配置来决定。Spring 默认的代理对象生成策略为:如果是目标类接口,则使用JDK动态代理技术,否则使用CGLib动态代理技术。
JDK动态代理: JDK动态代理主要通过java.lang.reflect 包中Proxy类和InvocationHandler接口来实现。InvocationHandler 是一个接口,不同的实现类定义不同的横切逻辑,并通过反射机制调用目标类的代码,动态地将横切逻辑和业务逻辑编制在一起。Proxy类利用InvocationHandler 动态创建一个符合某一 .接口的实例,生成目标类的代理对象。JDK 1.8中Proxy类的定义如下。
CGLib 动态代理: CGLib 即Code Generation Library, 它是一个高性能的代码生成类库,可以在运行期间扩展Java类和实现Java 接口。CGLib包的底层通过字节码处理框架ASM来实现,通过转换字节码生成新的类。
CGLib动态代理和JDK动态代理的区别: JDK只能为接口创建代理实例,而对于没有通过接口定义业务方法的类,则只能通过CGLib创建动态代理来实现。
五、Springmvc原理
SpringMVC框架是以请求为驱动,围绕Servlet设计,将请求发给控制器,然后通过模型对象,分派器来展示请求结果视图。其中核心类是DispatcherServlet,它是一个Servlet,顶层是实现的Servlet接口。
(1)客户端(浏览器)发送请求,直接请求到DispatcherServlet。
(2)DispatcherServlet根据请求信息调用HandlerMapping,解析请求对应的Handler。
(3)解析到对应的Handler后,开始由HandlerAdapter适配器处理。
(4)HandlerAdapter会根据Handler来调用真正的处理器开处理请求,并处理相应的业务逻辑。
(5)处理器处理完业务后,会返回一个ModelAndView对象,Model是返回的数据对象,View是个逻辑上的View。
(6)ViewResolver会根据逻辑View查找实际的View。
(7)DispaterServlet把返回的Model传给View。
(8)通过View返回给请求者(浏览器)
六、Springboot的启动流程
第一步:获取并启动监听器
第二步:构造容器环境
第三步:创建容器
第四步:实例化SpringBootExceptionReporter.class,用来支持报告关于启动的错误
第五步:准备容器
第六步:刷新容器
第七步:刷新容器后的扩展接口
七、线程与进程的区别
-
进程是程序的一次执行过程,是系统运行程序的基本单位,因此进程是动态的。系统运行一个程序即为一个进程的创建、运行以及消亡的过程。
-
线程是比进程更小的执行单位。一个进程在其执行的过程中可以产生多个线程,多个线程共享进程的堆和方法区内存资源,每个线程都有自己的程序计数器、虚拟机栈和本地方法栈。由于线程共享进程的内存,因此系统产生一个线程或者在多个线程之间切换工作时的负担比进程小得多,线程也称为轻量级进程。
-
进程和线程最大的区别是,各进程是独立的,而各线程则不一定独立,因为同一进程中的多个线程极有可能会相互影响。线程执行开销小,但不利于资源的管理和保护,进程则相反
八、线程之间怎么通信
1:同步(synchronized)
2:共享变量(volatile)
3:wait/notify()机制
4:管道通信就是使用java.io.PipedInputStream 和 java.io.PipedOutputStream进行通信
九、进程之间怎么通信
1、管道,匿名管道,命名管道
2、信号
3、信号量
4、消息队列
5、共享内存
6、socket
十、线程安全问题,怎么解决
当多个线程访问某个方法时,不管你通过怎样的调用方式或者说这些线程如何交替的执行,我们在主程序中不需要去做任何的同步,这个类的结果行为都是我们设想的正确行为,那么我们就可以说这个类是线程安全的。
synchronized关键字,就是用来控制线程同步的,保证我们的线程在多线程环境下,不被多个线程同时执行,确保我们数据的完整性,使用方法一般是加在方法上。
就是我们在需要的时候去手动的获取锁和释放锁,甚至我们还可以中断获取以及超时获取的同步特性,但是从使用上说Lock明显没有synchronized使用起来方便快捷
十一、常见的锁有哪些
公平锁
是指多个线程申请锁的顺序来获取锁,类似排队,先来后到。
在并发环境中,每个线程在获取锁时会查看此锁维护的等待队列,如果为空,或者当前线程是等待队列的第一个,就占有锁,否则就会加入到等待队列中,以后会按照FIFO的规则从队列中取到自己。
非公平锁
是指多个线程获取锁的顺序不是按照申请锁的顺序,有可能后申请的线程比先申请的线程优先获取锁;在高并发的情况下,有可能会造成优先级反转现象。非公平锁比较粗鲁,上来就直接尝试占有锁,如果尝试失败,就再采用类似公平锁那种方式。
可重入锁(递归锁)
指的是统一线程外层函数获取锁之后,内层递归函数仍然能获取该锁的代码,在同一个线程在外层方法获取锁的时候,在进入内层方法会自动获取锁。也就是说,线程可以进入任何一个它已经拥有的锁所同步着的代码块。
ReentrantLock/Synchronized 就是典型的可重入锁,可重入锁最大的作用是避免死锁 。
自旋锁
自旋锁(spinlock):是指尝试获取锁的线程不会立即阻塞,而是采用循环的方式去尝试获取锁,这样的好处是减少上下文切换的消耗,缺点就是循环会消耗CPU。
独占锁(写锁)/共享锁(读锁)/互斥锁
独占锁:指该锁一次只能被一个线程所持有。对 ReentrantLock/Synchronized 而言都是独占锁
共享锁:指该锁可被多个线程所持有。对 ReentrantReadWriteLock 其读锁是共享锁,其写锁是独占锁。读锁的共享锁可保证并发读是非常高效的,读写、写读、写写的过程是互斥的。
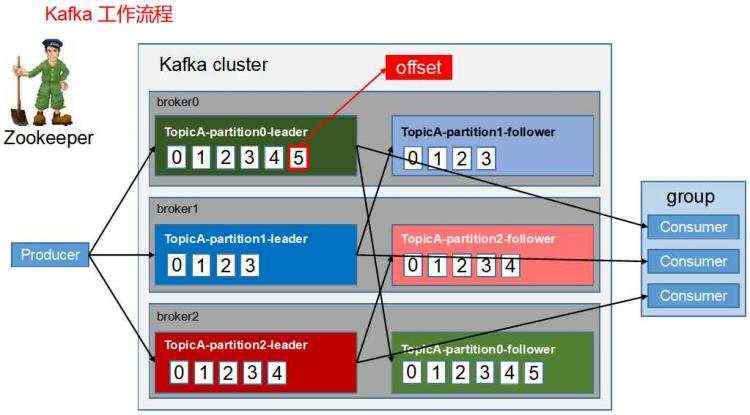
十二、Kafka的底层原理,为什么那么快?
在 Kafka 中一个概念叫做 Partition ,分区的意思用来存储消息,生产者生产的消息都是从末尾进行添加。Kafka不进行实时的消息删除,而是在某个时间进行批量删除的,这个比单个删除效率要高。
页缓存
Kafka 避免使用 JVM,直接使用操作系统的页缓存特性提高处理速度,进而避免了JVM GC 带来的性能损耗。
零拷贝
作为 Kafka 运行在 Linux 操作系统,作为 Linux 操作系统,它有一个特性叫做零拷贝。就是在用户态与内核态不再发生拷贝。
当数据需要操作会加载到内核态的页缓存中,需要发送是再加载到 socket 缓冲区中。其中就少了与用户态之间的 copy 动作,如果再处理海量数据的时候,效率就提高了很多。
批量操作
在 kafka 中页提高了大量批处理的 API ,可以对数据进行统一的压缩合并,通过更小的数据包在网络中进行数据发送,再进行后续处理,这在大量数据处理中,效率提高是非常明显的。
十三、为什么不用其它MQ,而使用Kafka?
RabbitMQ:分布式,支持多种MQ协议,重量级
ActiveMQ:与RabbitMQ类似
Redis:单机、纯内存性好,持久化较差
Kafka:分布式,消息不是使用完就丢失【较长时间持久化】,吞吐量高【高性能】,轻量灵活
Kafka 的亮点,天生是分布式的,不需要你在上层做分布式的工作,另外有较长时间持久化,前面的几个MQ基本消费就干掉了,另外在长时间持久化下性能还比较高,顺序读和顺序写,另外还通过sendFile这样0拷贝的技术直接从文件拷贝到网络,减少内存的拷贝,还有批量读批量写来提高网络读取文件的性能
十四、抽象类和接口的区别,以及使用方面?
相同点:
① 抽象类和接口都不能被实例化
② 抽象类和接口都可以定义抽象方法,子类/实现类必须覆写这些抽象方法
不同点:
① 抽象类有构造方法,接口没有构造方法
② 抽象类可以包含普通方法,接口中只能是public abstract修饰抽象方法(Java8之后可以)
③ 抽象类只能单继承,接口可以多继承
④ 抽象类可以定义各种类型的成员变量,接口中只能是public static final修饰的静态常量
抽象类和接口的使用场景
1.抽象类的使用场景
既想约束子类具有共同的行为(但不再乎其如何实现),又想拥有缺省的方法,又能拥有实例变量
如:模板方法设计模式,模板方法使得子类可以在不改变算法结构的情况下,重新定义算法中某些步骤的具体实现。
2.接口的应用场景
① 约束多个实现类具有统一的行为,但是不在乎每个实现类如何具体实现
② 作为能够实现特定功能的标识存在,也可以是什么接口方法都没有的纯粹标识。
③ 实现类需要具备很多不同的功能,但各个功能之间可能没有任何联系。
④ 使用接口的引用调用具体实现类中实现的方法(多态)
十五、Redis的持久化机制详细说明?
(1) RDB (Redis DataBase): RDB在指定的时间间隔内对数据进行快照存储。RDB的特点在于:文件格式紧凑,方便进行数据传输和数据恢复;在保存.rdb快照文件时父进程会fork 出一个子进程,由子进程完成具体的持久化工作,所以可以最大化Redis 的性能;同时,与AOF相比,在恢复大的数据集时会更快一些。
(2) AOF ( Append Of Flie): AOF记录对服务器的每次写操作,在Redis重启时会重放这些命令来恢复原数据。AOF命令以Redis 协议追加和保存每次写操作到文件末尾,Redis还能对AOF文件进行后台重写,使得AOF文件的体积不至于过大。AOF的特点有:可以使用不同的fsync 策略(无fsync、每秒fsync、每次写的时候fsync )将操作追加命令到文件中,操作效率高;同时,AOF文件是日志的格式,更容易被理解和操作。







 京公网安备 11010802041100号
京公网安备 11010802041100号